Hadoop怎么實現集群搭建
這篇文章主要為大家展示了“Hadoop怎么實現集群搭建”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Hadoop怎么實現集群搭建”這篇文章吧。
銅官網站制作公司哪家好,找成都創新互聯!從網頁設計、網站建設、微信開發、APP開發、響應式網站等網站項目制作,到程序開發,運營維護。成都創新互聯于2013年創立到現在10年的時間,我們擁有了豐富的建站經驗和運維經驗,來保證我們的工作的順利進行。專注于網站建設就選成都創新互聯。
主要環境:
CentOS6.4
JDK 1.6
Hadoop 1.2.1
使用三臺機器進行搭建。
Master(NameNode、SecondaryNameNode、JobTracker):10.0.0.13
Slave(DataNode、TaskTracker):10.0.0.15
Slave(DataNode、TaskTracker):10.0.0.16
1.三臺機器都配置/etc/hosts文件

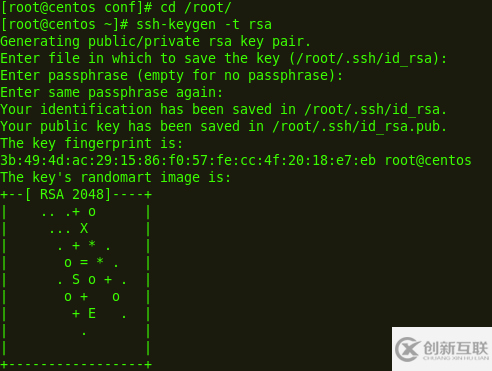
2.配置ssh免密碼連接,在每臺機器上均運行ssh-keygen -t rsa ,之后將每臺機器生成的
id_rsa.pub合并為authorized_keys,并復制到每臺機器上

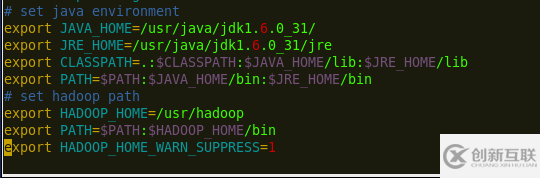
3.配置hadoop目錄下的conf/hadoop-env.sh 中的java環境變量

4.修改hdfs-site.xml 修改hdfs中數據塊要復制多少份

5.修改mapred-site.xml 配置jobtracker

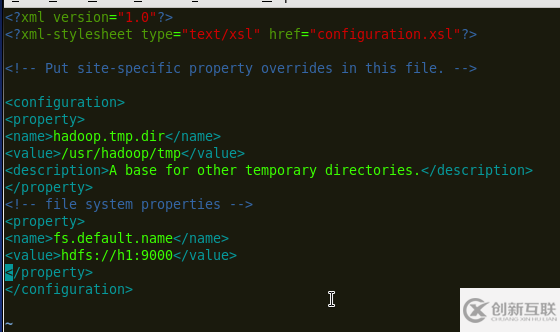
6.修改core-site.xml 指定數據目錄(使用mkdir創建/usr/hadoop/tmp目錄)
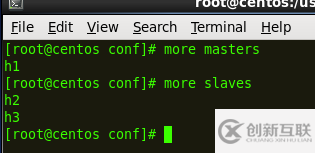
7.修改masters和slaves
8.使用scp命令將hadoop目錄復制到各個節點
9.并在每個節點配置hadoop環境變量(編輯/etc/profile 立即生效source /etc/profile)
10.格式化

11.啟動hadoop運行start-all.sh

12.最后使用jps驗證是否啟動相應java進程
Master:
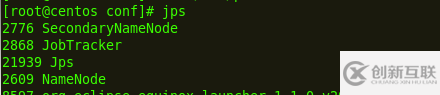
Slave:
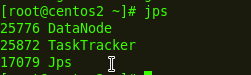
以上是“Hadoop怎么實現集群搭建”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注創新互聯行業資訊頻道!
標題名稱:Hadoop怎么實現集群搭建
URL鏈接:http://m.2m8n56k.cn/article42/iesoec.html
成都網站建設公司_創新互聯,為您提供定制網站、手機網站建設、App開發、用戶體驗、Google、品牌網站建設
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:[email protected]。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 外貿建站零基礎——搭建網站 2022-12-22
- 談談外貿建站為什么要選擇香港服務器? 2022-10-03
- 外貿建站選美國空間還是香港空間好? 2022-10-10
- 外貿建站需要哪些東西??? 2014-07-23
- 外貿建站中的那些細節影響著網站流量? 2015-04-24
- 外貿建站系統如何選,要從不同角度去分析 2022-05-27
- 自助外貿建站不等于企業網站建設 2016-03-19
- 海珠區外貿建站公司:專注歐美英文網頁設計制作! 2016-02-07
- 開發好的APP如何獲取用戶,告訴你了你也不一定領悟明白! 2022-06-02
- 外貿建站選擇香港主機都有哪些優勢? 2022-10-10
- 外貿建站的推廣方式有哪些 2016-04-18
- 外貿建站租用香港云服務器還是美國云服務器好? 2022-10-02