利用python爬蟲怎么爬取虎牙直播-創(chuàng)新互聯(lián)
本篇文章給大家分享的是有關(guān)利用python爬蟲怎么爬取虎牙直播,小編覺得挺實用的,因此分享給大家學(xué)習(xí),希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。

# 獲取所有的主播信息
def getDatas(html):
datalist=[]
parse=parsel.Selector(html)
lis=parse.xpath('//li[@class="game-live-item"]').getall()
# print(lis)
for li in lis:
data = []
parse1=parsel.Selector(li)
img_src=parse1.xpath('//img[@class="pic"]/@data-original').get("data")
data.append(img_src)
title=parse1.xpath('//i[@class="nick"]/@title').get("data")
data.append(title)
redu=parse1.xpath('//i[@class="js-num"]/text()').get("data")
data.append(redu)
datalist.append(data)
return datalist這樣我們就能獲取到我們所需要的所有資源,之后將圖片保存下來即可。這其中有兩種文件的下載方式,一種是通過with open打開文件的方式 ,另外一種就是通過urllib.request.urlretrieve(data,path) 的方法,網(wǎng)上說第二種方式的下載速度會相對快一點,并且第二種有點set 集合的意思,可以自動進行去重 的操作,下載的文件夾中沒有該文件就下載,否則就跳過。
#保存主播頭像
def download(datalist):
for data in datalist:
#第一種下載方式
with open("D:/software/python/python爬蟲/虎牙顏值主播排名/", 'wb') as f:
f.write(data[0])
#第二種下載方式
urllib.request.urlretrieve(data[0],"D:/software/python/python爬蟲/虎牙顏值主播排名"+"/"+data[1]+".jpg")
print(data[1]+"下載完成")百度人臉識別接口
百度AI開放平臺鏈接:https://ai.baidu.com/
輸入相應(yīng)的應(yīng)用名稱以及簡介即可。
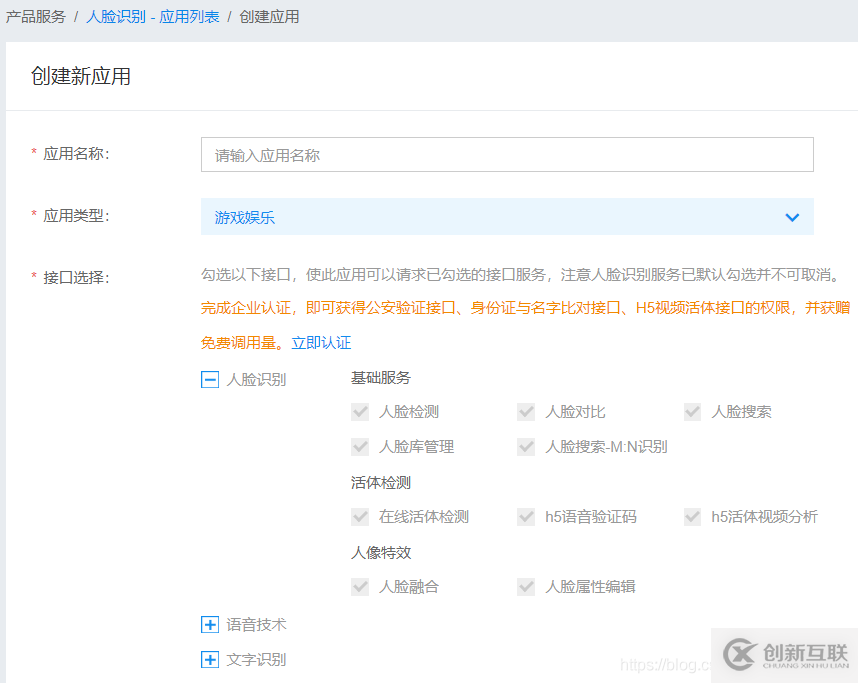
這樣我們的應(yīng)用就算創(chuàng)建完畢了。選中的部分也是我們接下來會用到的。

之后我們先去看一下sdk文件
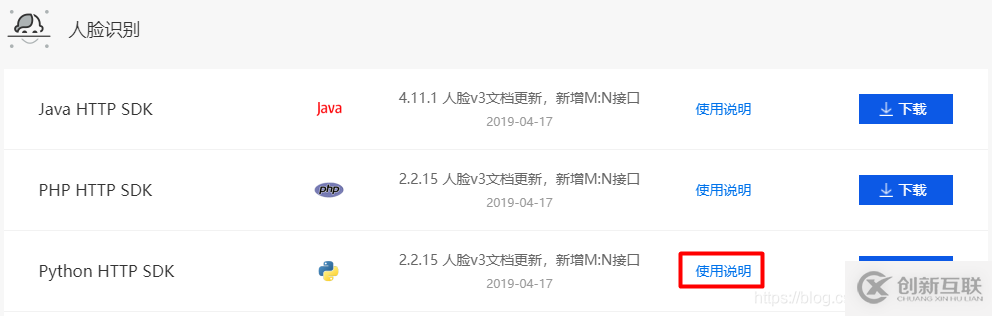
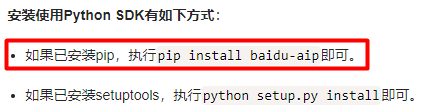
看使用說明即可,不用著急下載,之后我們直接在pycharm中安裝模塊就行。
之后我們來看一下簡單的操作流程首先先創(chuàng)建客戶端:

之后我們就是調(diào)用接口解析圖片,因為我們需要返回顏值分數(shù)這一個參數(shù),所以還需要帶參數(shù)進行請求,否則無法將分數(shù)信息返回給我們。如下圖:

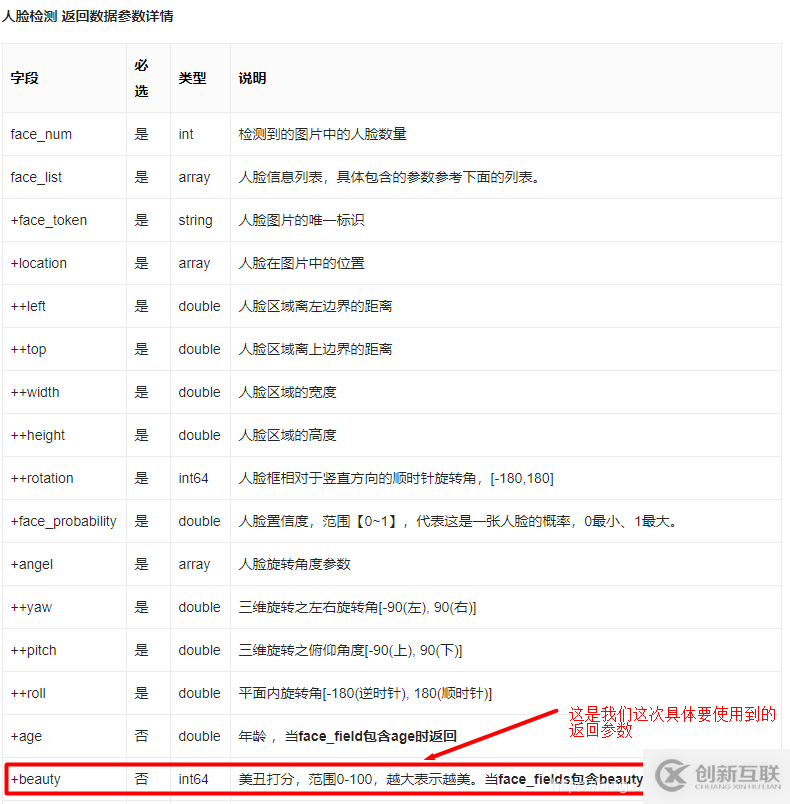
這樣我們顏值檢測的接口流程基本就已經(jīng)理清楚了,代碼如下:
def face_rg(file_path):
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipFace(APP_ID, API_KEY, SECRET_KEY)
with open(file_path,'rb')as file:
data=base64.b64encode(file.read())
image=data.decode()
imageType = "BASE64"
""" 如果有可選參數(shù) """
options = {}
options["face_field"] = "beauty"
""" 帶參數(shù)調(diào)用人臉檢測 """
result=client.detect(image, imageType, options)
# print(result)
return result['result']['face_list'][0]['beauty']之后我們就只需要編寫一個遍歷文件夾下面的圖片進行檢測,之后將整個信息按照顏值分數(shù)進行降序排列:
path=r"D:\software\python\python爬蟲\虎牙顏值主播排名"
image_list=os.listdir(path)
name_score={}
for image in image_list:
try:
print(image.split(".")[0]+"顏值評分為:%d"%face_rg(path+"/"+image))
name_score[image.split(".")[0]]=face_rg(path+"/"+image)
except:
pass
second_score=sorted(name_score.items(),key=lambda x:x[1],reverse=True)
print("-------------------------------------檢測結(jié)束-------------------------------------")
print("-------------------------------------以下是排名-------------------------------------")
for a,b in enumerate(second_score):
print("{}的顏值評分為:{},排名第{}".format(second_score[a][0],second_score[a][1],a+1))以上就是利用python爬蟲怎么爬取虎牙直播,小編相信有部分知識點可能是我們?nèi)粘9ぷ鲿姷交蛴玫降摹OM隳芡ㄟ^這篇文章學(xué)到更多知識。更多詳情敬請關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道。
本文題目:利用python爬蟲怎么爬取虎牙直播-創(chuàng)新互聯(lián)
網(wǎng)址分享:http://m.2m8n56k.cn/article46/dccjhg.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站收錄、微信公眾號、網(wǎng)站排名、搜索引擎優(yōu)化、外貿(mào)建站、網(wǎng)站建設(shè)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:[email protected]。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 云計算學(xué)習(xí)路線圖素材課件,Linux中軟件安裝的方式-創(chuàng)新互聯(lián)
- OSI網(wǎng)絡(luò)七層分層理解-創(chuàng)新互聯(lián)
- 一個初學(xué)者如何學(xué)好php-創(chuàng)新互聯(lián)
- c語言中的/和%表示什么意思在C語言中主函數(shù)的個數(shù)是多少個?-創(chuàng)新互聯(lián)
- PHP的類與對象-創(chuàng)新互聯(lián)
- HTML標簽的marginwidth屬性怎么用-創(chuàng)新互聯(lián)
- myeclipse安裝soapui插件-創(chuàng)新互聯(lián)

- 自建云服務(wù)器的作用,自建云存儲服務(wù)器的優(yōu)勢 2022-10-07
- 云服務(wù)器相對于傳統(tǒng)服務(wù)器有什么優(yōu)點? 2022-10-02
- 云服務(wù)器將成趨勢 計算力和安全性是考驗 2021-02-23
- 服務(wù)器之家淺談香港云服務(wù)器的四大用處 2022-10-05
- 免備案香港服務(wù)器和非免備案云服務(wù)器有什么區(qū)別? 2022-10-12
- 云服務(wù)器bcc是什么?有哪些特點? 2022-10-10
- 如何選擇適合鄭州做網(wǎng)站公司的云服務(wù)器 2023-03-27
- 手游開發(fā)商怎么選擇云服務(wù)器? 2022-10-07
- 建網(wǎng)站應(yīng)該買什么云服務(wù)器 2021-02-10
- 香港云服務(wù)器該怎么防止惡意攻擊? 2022-10-08
- 日本云服務(wù)器有什么特性?好不好? 2022-10-02
- 虛擬主機、VPS主機、云服務(wù)器有什么區(qū)別,哪個更好? 2017-01-04