Google開源TensorFlow強化學習框架示例分析-創新互聯
Google開源TensorFlow強化學習框架示例分析,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。

谷歌宣布開源基于 TensorFlow 的強化學習框架——Dopamine。
強化學習是一種人工智能(AI)技術,它使用獎勵(或懲罰)來驅動agent朝著特定目標前進,比如之前大火的Alpha Go擊敗人類頂尖圍棋選手,還有在 Dota2 對戰人類職業玩家的Open AI Five。同時,強化學習也是DeepMind 的深度Q 網絡(DQN)的核心部分,可以在多個workers 中分配學習,例如,在Atari 2600游戲中實現“超人”性能。麻煩的是,強化學習框架需要時間來掌握一個目標,往往是不靈活的,也不夠穩定。
這就是谷歌提出替代方案的原因:基于TensorFlow的開源強化學習框架——Dopamine,從今天開始,它可以從Github獲得。
(https://github.com/google/dopamine/tree/master/docs#downloads)
谷歌研究人員表示,他們開源的這個 TensorFlow 強化學習框架強調三點:靈活、穩定和可重復性。
受到主要組件之一大腦中獎勵動機行為行為的啟發,以及反映神經科學和強化學習的研究之間的聯系,這個平臺的目的是使推測性研究推動根本性的發現,此版本還包括一組闡明如何使用整個框架的colabs。
易用性
為此,它包括了一套精心編寫的代碼(15個Python文件),專注于Arcade學習環境(一個用視頻游戲評估AI技術的平臺)以及四種不同的機器學習模型:上述提到的深度Q 網絡(DQN); C51; Rainbow agent的一個簡化版本; Implicit Quantile Network agent。清晰和簡潔是這個框架設計中的兩個關鍵考慮因素。
可重復性
為了實現強化學習的可重復性,代碼在Arcade學習環境支持的60個游戲中提供完整的測試覆蓋率和訓練數據(采用JSON和Python pickle格式),并遵循標準化結果以進行實證評估的最佳實踐。
基準測試
對于新的研究者來說,對自己的想法進行快速的基準測試是非常重要的。谷歌提供四個智能體的完整訓練數據,包括ALE 支持的60 個游戲,格式為Python pickle 文件(對于使用谷歌框架訓練的智能體)和JSON 數據文件(用于對比其他框架訓練的智能體)。谷歌還提供了一個網站,研究者可以使用該網站對所有提供智能體在所有60 個游戲中的訓練運行進行快速可視化。

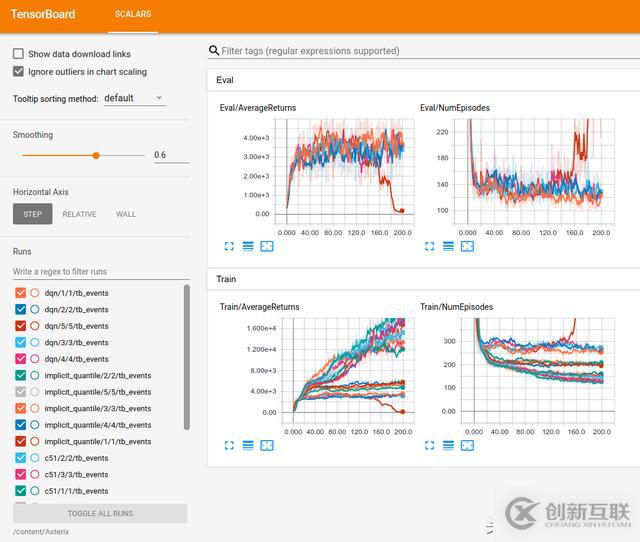
谷歌的4 個智能體在Seaquest 上的訓練運行(Seaquest 是ALE 支持的Atari
除此之外,谷歌還推出了一個網站,允許開發人員將多個訓練中智能體的運行情況快速可視化。它還提供經過訓練的模型、原始統計日志和TensorFlow event files,用于TensorBoard動態圖的繪制,TensorBoard是一個web應用可視化套件。
“我們的希望是,我們的框架的靈活性和易用性將使研究人員能夠嘗試新的思想,無論是漸進的還是激進的。”
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注創新互聯-成都網站建設公司行業資訊頻道,感謝您對創新互聯的支持。
當前題目:Google開源TensorFlow強化學習框架示例分析-創新互聯
網頁路徑:http://m.2m8n56k.cn/article5/dspjoi.html
成都網站建設公司_創新互聯,為您提供App開發、商城網站、服務器托管、品牌網站設計、標簽優化、網站收錄
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:[email protected]。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 淺談網站策劃的影響及流程 2021-12-15
- 建網站:營銷型網站策劃的重要性 2022-02-26
- 網站建設與網站策劃的關系 2016-11-05
- 企業網站策劃書該如何進行設計? 2021-04-30
- 濟寧網站建設-網站策劃需要做的具體工作 2021-11-27
- 一個優質的網站策劃方案離不開seo優化推廣的技術支持 2016-11-25
- 網站設計與網站策劃 2021-04-20
- 營銷型網站策劃書范文 2022-05-27
- 網站策劃到底對于網絡公司有多重要 2016-11-03
- 未來的網站策劃五大趨勢 2021-01-09
- 網站策劃——網站建設的靈魂 2022-12-01
- 想要做出好的營銷型網站策劃制作方案,要注意哪些要點? 2022-07-27